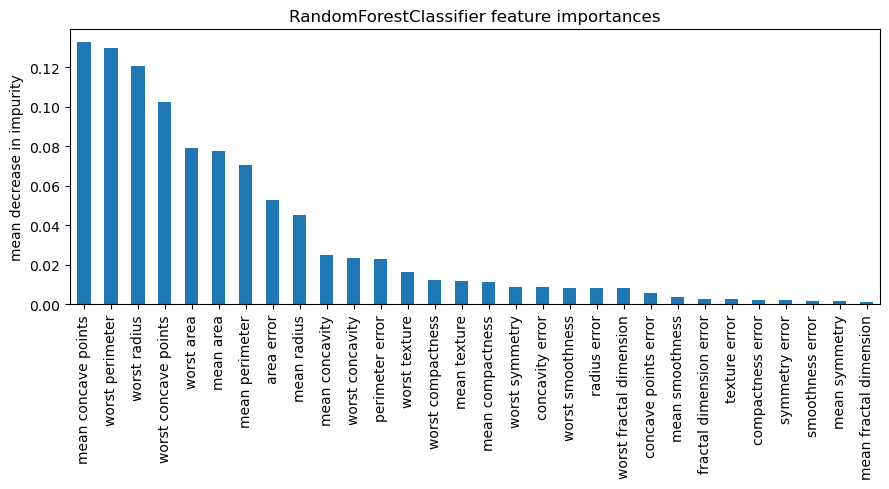
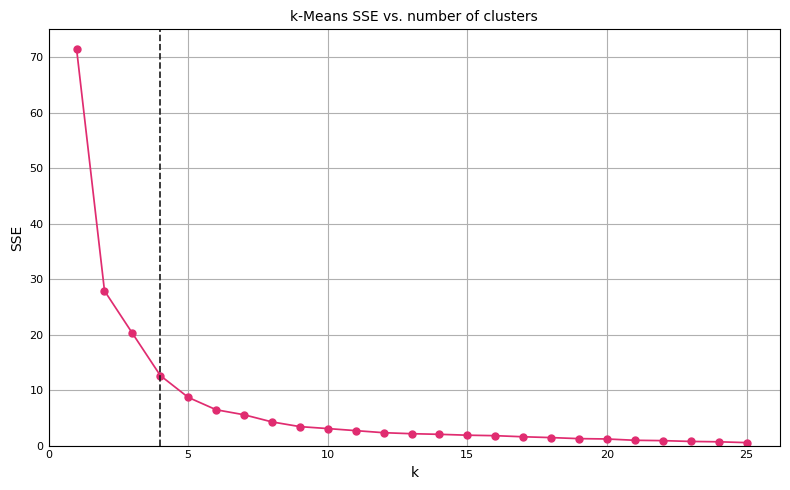
Hyperparameter Search and Classifier Threshold Selection
The following notebook demonstrates how to use GridSearchCV to identify optimal hyperparameters for a given model and metric, and alternatives for selecting a classifier threshold in scikit-learn.
First we load the breast cancer dataset. We will...