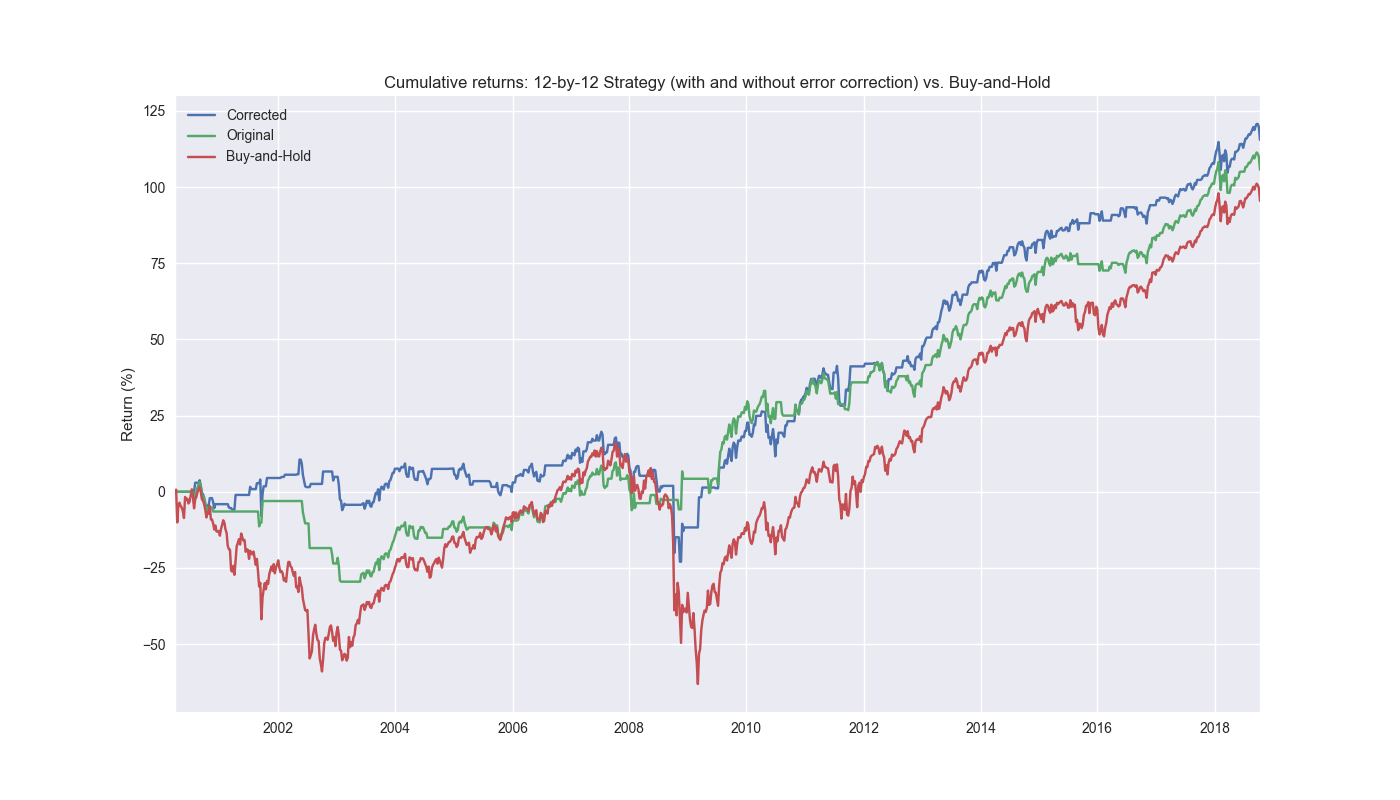
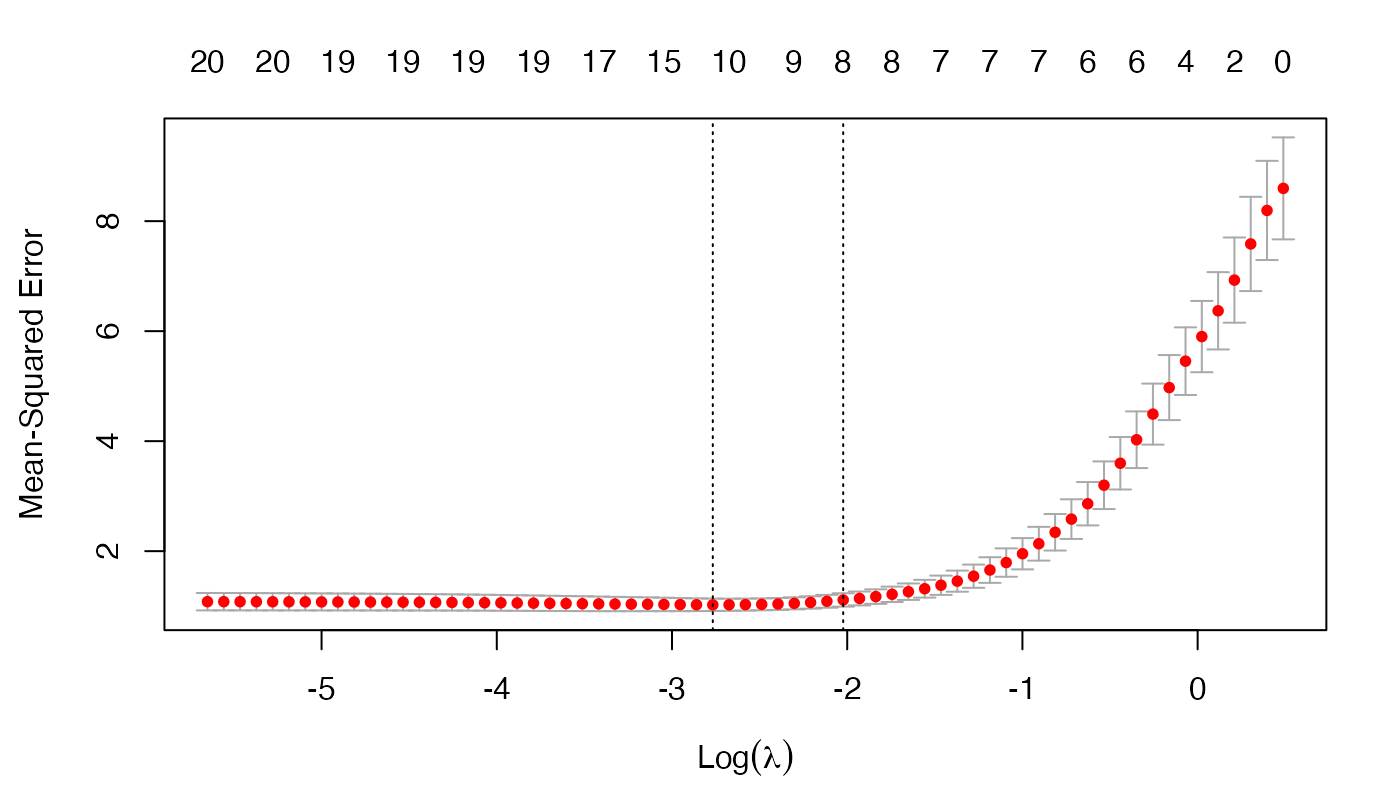
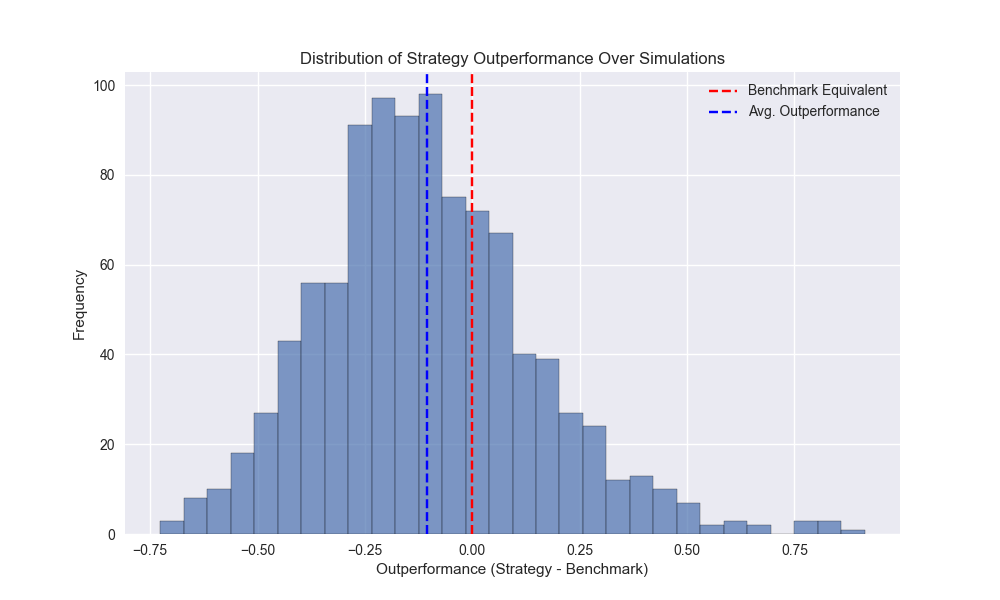
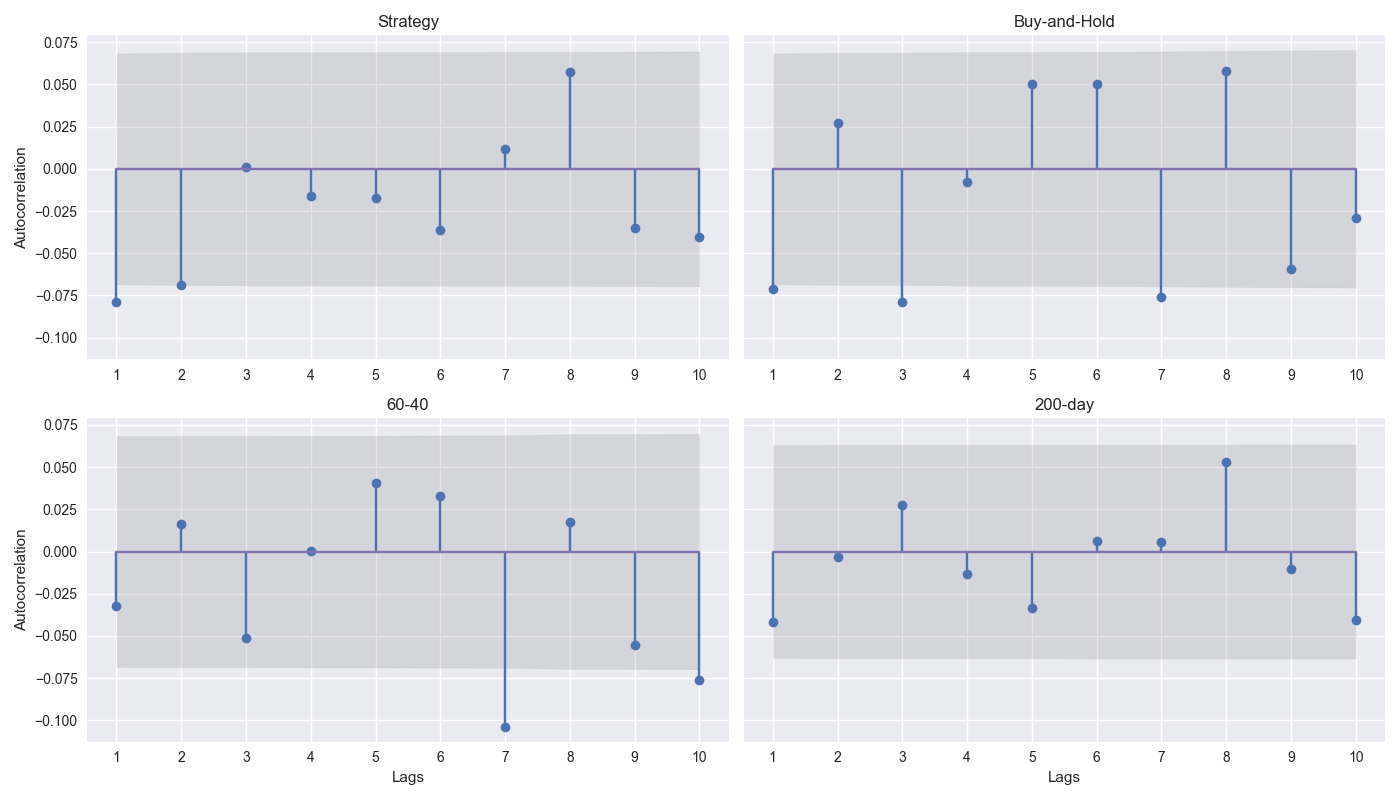
Day 22: Error Correction
On Day 21, we wrung our hands with frustration over how to proceed. The results of our circular block sampling suggested we shouldn’t expect a whole lot of outperformance in our 12-by-12 model out-of-sample. To deal with this our choices were, back ...