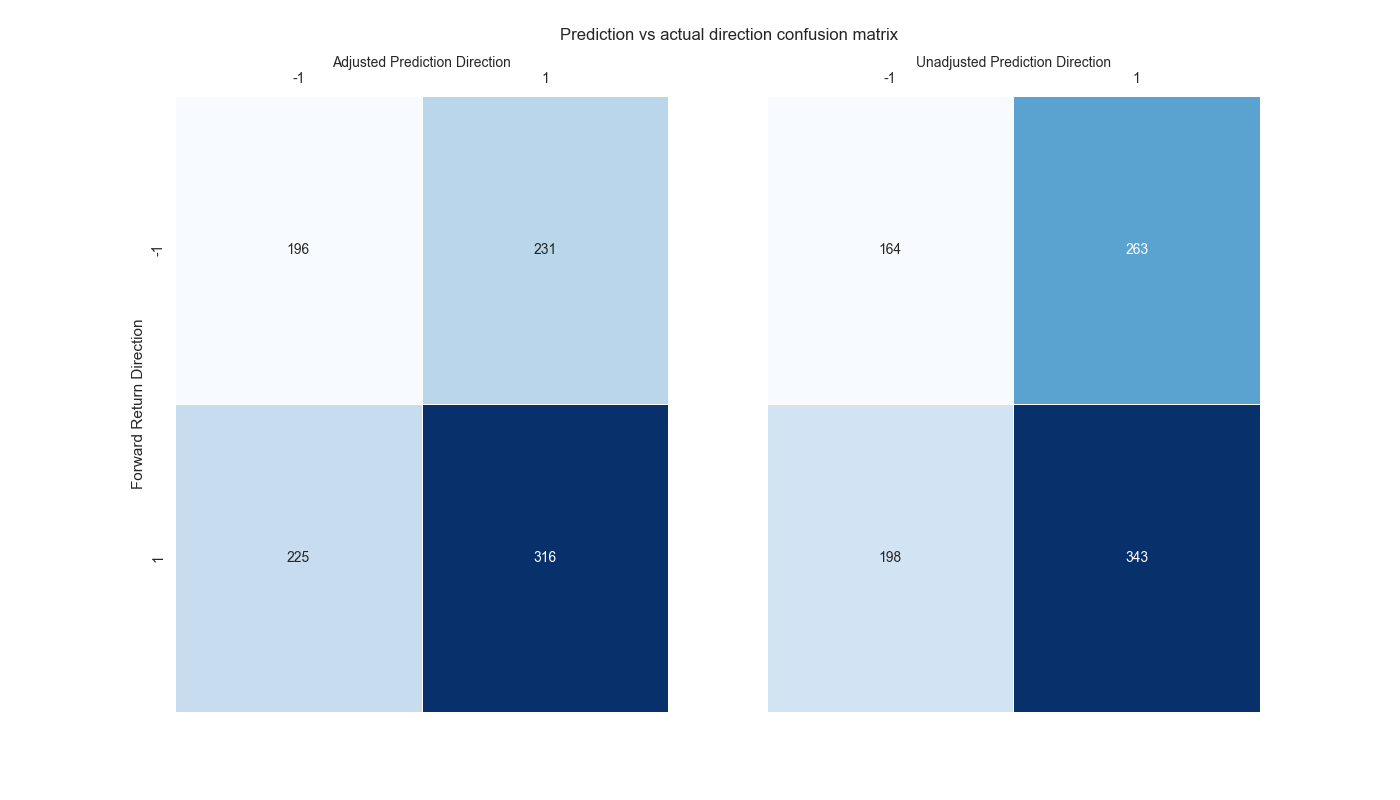
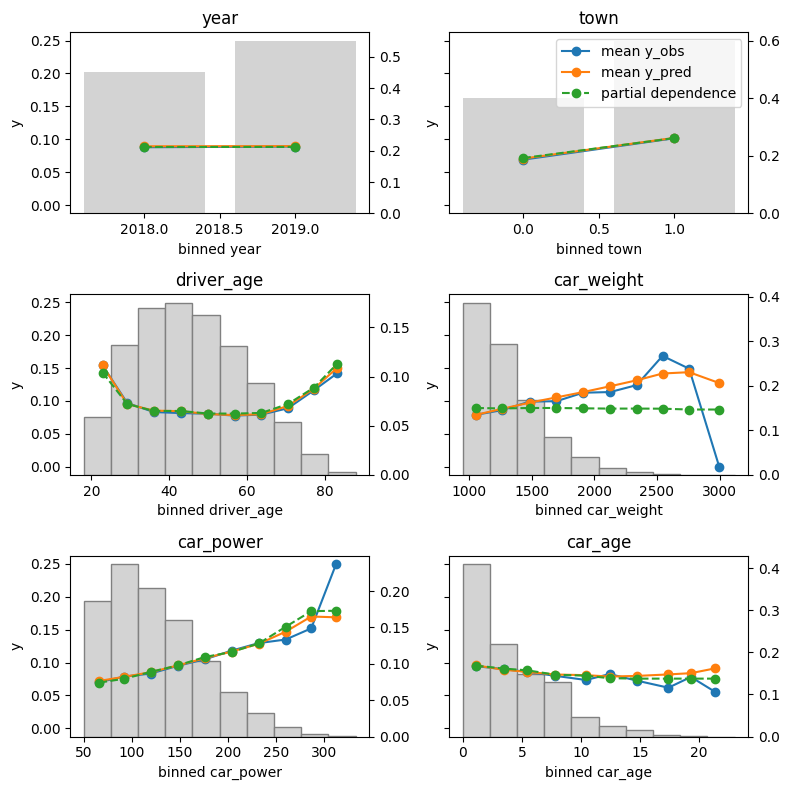
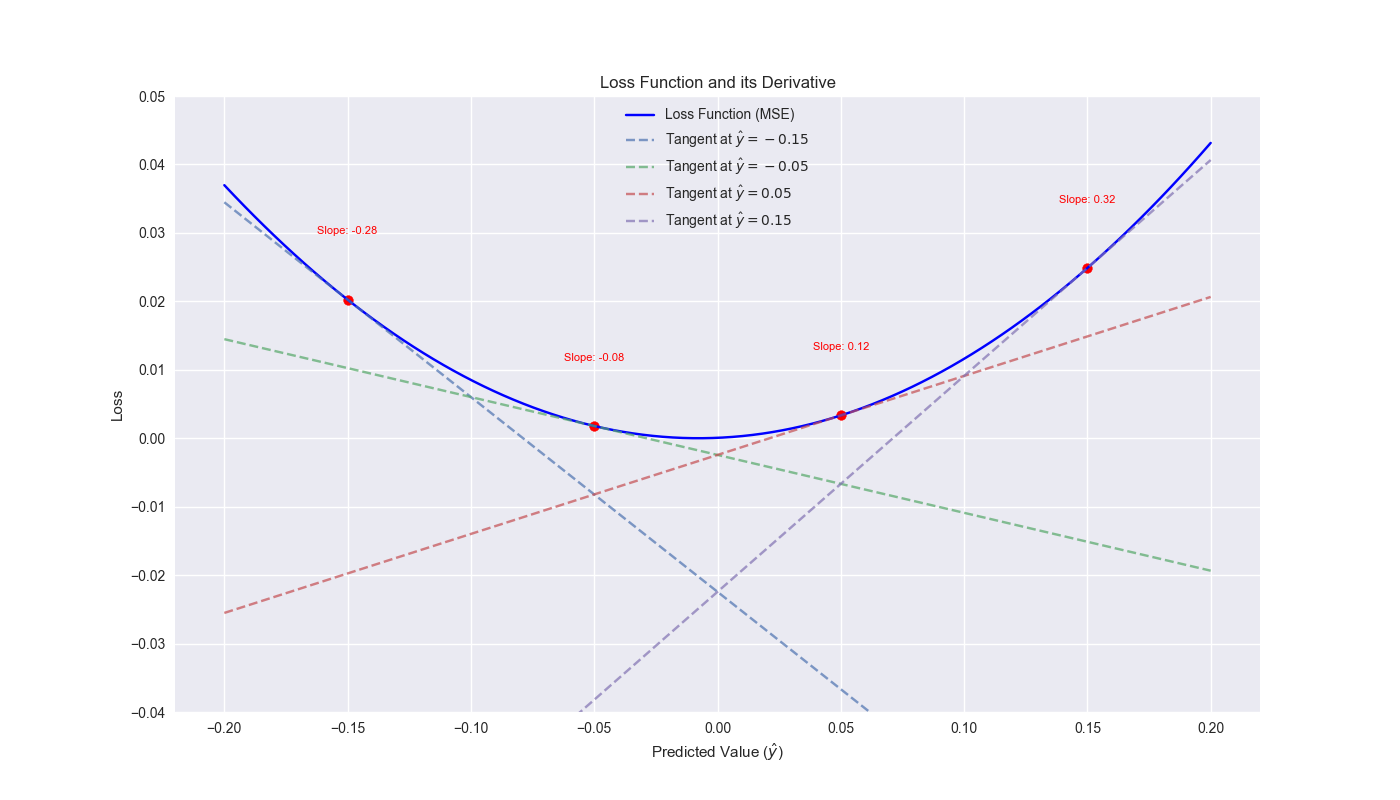
The Benefits of Fully Utilizing UX/UI Design Throughout the Project Journey for Extractable
Quite often, the involvement of a designer in a project is temporary, depending on the budget, deadlines, planning, etc. This approach is mainly used in projects with small budgets or at the POC stages, where a working prototype needs to be built to test hypotheses. From a utilization standpoint, this ...