How to Train a Python-Based AI Text Summarizer?
Want to share your content on python-bloggers? click here.
Python is one of the leading development/coding languages and PyPL’s research puts it ahead of all others as it has a 29% market share. Now, the widely popular language isn’t just used for one sort of programming or another as it is employed by many developers as well as companies and experts.
And a number of them use Python and its extensive libraries to create and train their own AI Text Summarizers. So, how do you train a Python-based AI text summarizer? What are some of the key algorithms? And which types of summarizations can it do? Let’s find out.
2 Types of Summarizations
Summarization is of two main types, and it’s important to understand which ones they are. While we’ll talk about technicalities later, we’re only talking about the type of summarizations you can expect in this section. So, let’s explore them:
1: Extractive Text Summarization
Extractive Text Summarization is when the text is summarized by picking up a few key points from the original text. It sometimes features the same words and phrases as the primary content and usually offers a basic look at the content.
The three main features of extractive text summarization include:
- Sentence Selection
- Content Preservation
- Algorithmic Processing
The first part, sentence selection, is where tools or trained platforms identify key sentences from the original text. Then, content preservation keeps words and structure the same while doing the summary. Algorithmic processing finally merges it together to produce a summary.
2: Abstractive Text Summarization
Abstractive Text Summarization, as the name suggests, is the abstract and summary of the original text. So, it captures key points and concepts from the content and then produces a summary in new and unique words, which presents an abstract of the main text.
The three main features of abstractive summaries are:
- Semantic Understanding
- Paraphrasing and Rewriting
- Contextualization
The first phase of abstractive summarizing deals with understanding the meaning of the text, and capturing the basic concept. Then, paraphrasing and rewriting kicks in, as it rewrites the text in new words while conveying the main idea.
Lastly, contextualization ensures the content remains within the boundaries of the main text. That’s why, abstractive summaries are usually all-inclusive and better than extractive summaries.
2 Main Ways to Train Python-Based AI Text Summarizers
Now let’s discuss the top three ways to train Python-based AI text summarizers. While there are many ways to do it, these two ways stand out to be the best:
- Sumy
- GPT-3
- Gensim
Now, let’s show you how each one works and how they can be trained in Python to generate summaries:
1: Sumy
Sumy is a library in Python, which is trained to perform text summarization. It employs a variety of algorithms to execute said summaries, including LexRank, Luhn, and LSA. Sumy does extractive summarizations, and that’s why the summaries aren’t really all-encompassing.

However, it’s one of the top libraries in Python used for summarization. So, here’s how each of its algorithms works:
LexRank:
The LexRank version of the algorithm looks like this:
Simply copy and paste this code to summarize any text between the two quotations (“”).
Luhn:
Luhn is more or less similar, and it’s named after the IBM researcher Hans Peter Luhn. The algorithm is quite simple and easier to memorize compared to the earlier LexRank algorithm. Here’s how it goes:

LSA:
LSA or Latent Semantic Analysis is another great algorithm and it operates on automation. In other words, it uses the term frequency, and it’s perhaps the closest to the definition of an extractive summarizer. The code for LSA looks like this:

2: GPT-3
It could be argued that GPT-3 is the most complicated of all the Python models and it uses extensive techniques to create abstractive summaries. The purpose of GPT is to extract the content’s main concept and then produce a summary.

Now, as the title GPT-3 suggests, there was also GPT-2 but the latest API offers much more capabilities than the predecessor. So, the first thing to train in Python is to download the dependencies needed to run GPT-3-based summarization, with this code:
Then, you have to download PDF or other documents from the internet to perform the said summarization, and here is the code for that:
The URL of the PDF or text file will go between the two quotation marks. From there, you need to convert the PDF into text, and then the GPT-3 model will be able to read it. Here’s how to do that:
And finally, you will trigger GPT-3 to summarize the text that you have gathered, and here’s how to do that:

After that, you can also use the “Paper content” command from OpenAI to yield the summarized result in whatever format that you like.
GPT-Trained AI Text Summarization with a Tool
As a user, you don’t need to through all this coding hassle because there are tools like Summarizer.org which employ the same GPT-3 models. This means you can just use the tool to write an abstract summary without the hassle.
An AI Text Summarizer like this allows you to simply input the text you wish to turn into a summary. And since Summarizer.org uses GPT-3, we can expect abstractive summaries, like this:
Once you put in the content, it only takes a second to tap the “Summarize” button to begin:
And then you get the abstractive summary after a few seconds:
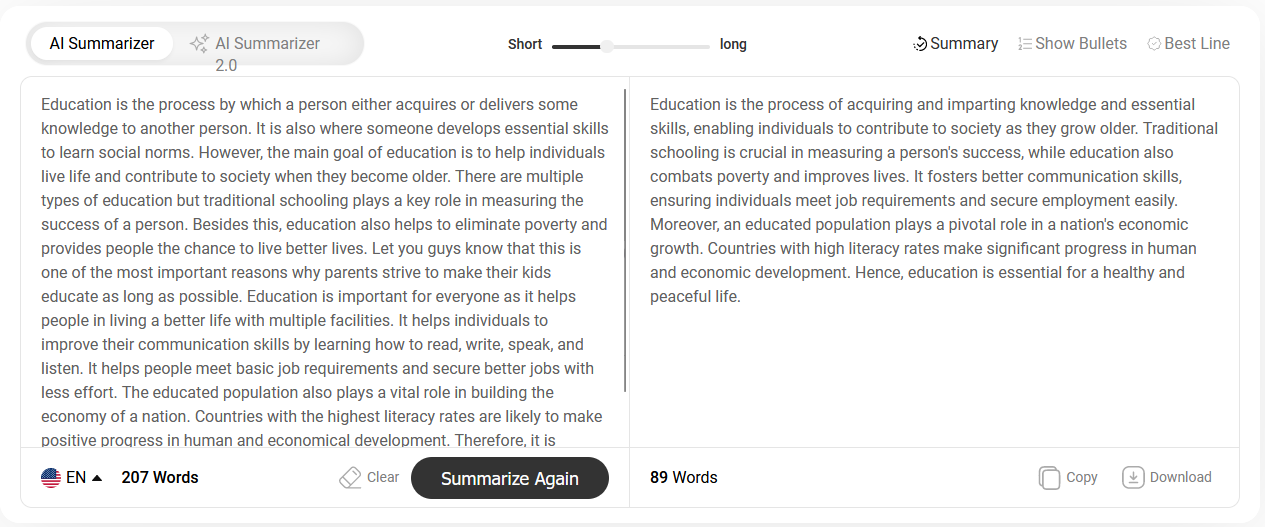
From there, you can either copy or download it, or you can check other summary types, such as:
Bullets:

Best Line:

This sort of tool can save the hassle of training your own Python-based AI text summarizer. But, it can also show you a demonstration of how well good algorithms like GPT-3 work when summarizing text.
Conclusion
These are some of the best ways to train a Python-based AI text summarizer. It’s important to use the right libraries from Python to train a summarizer. And the ones we used, aka Sumy and GPT-3 are best in their respective categories of abstractive and extractive summaries. Therefore, make sure you understand the basics of each library or algorithm before working with it.
Want to share your content on python-bloggers? click here.