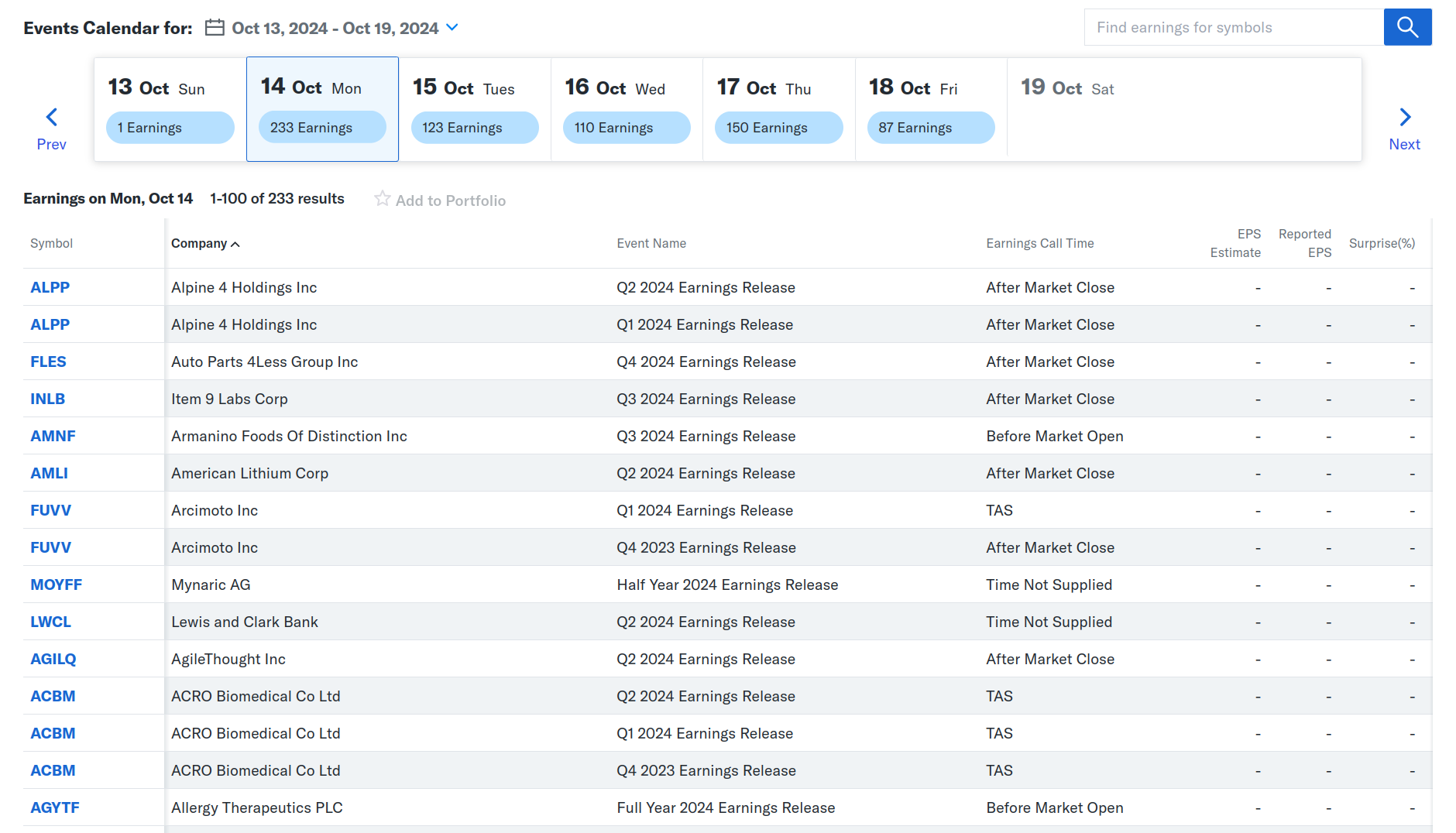
Evaluating a New Job Market Data Feed
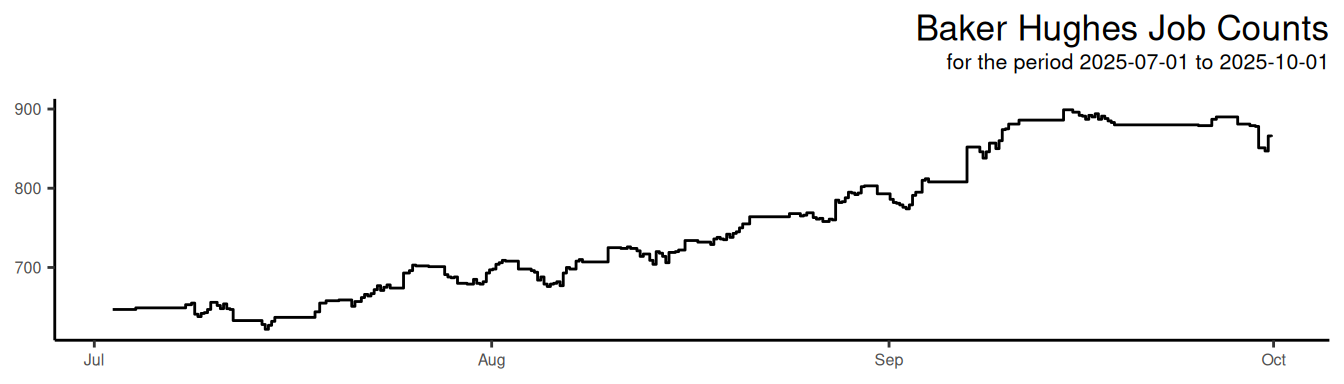
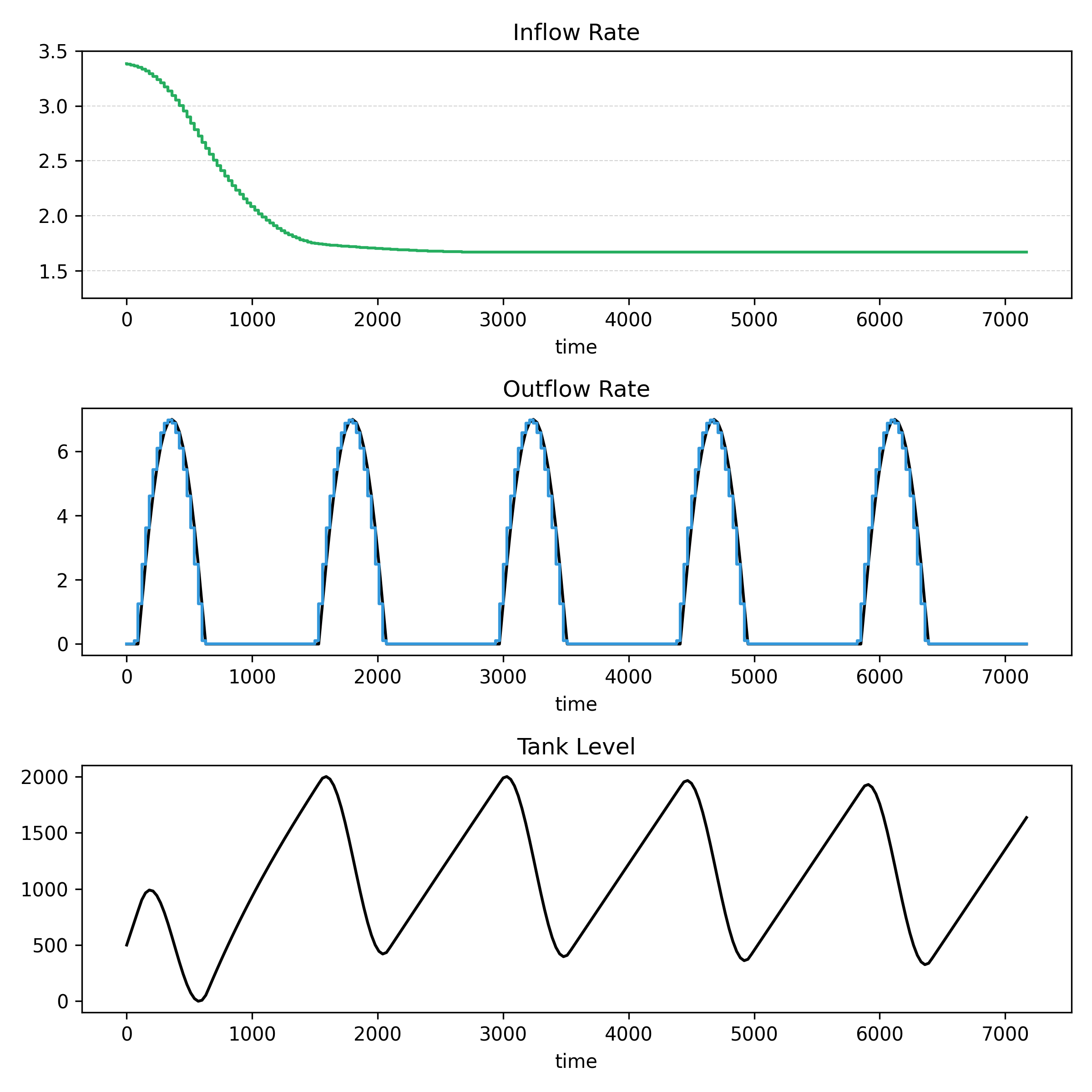
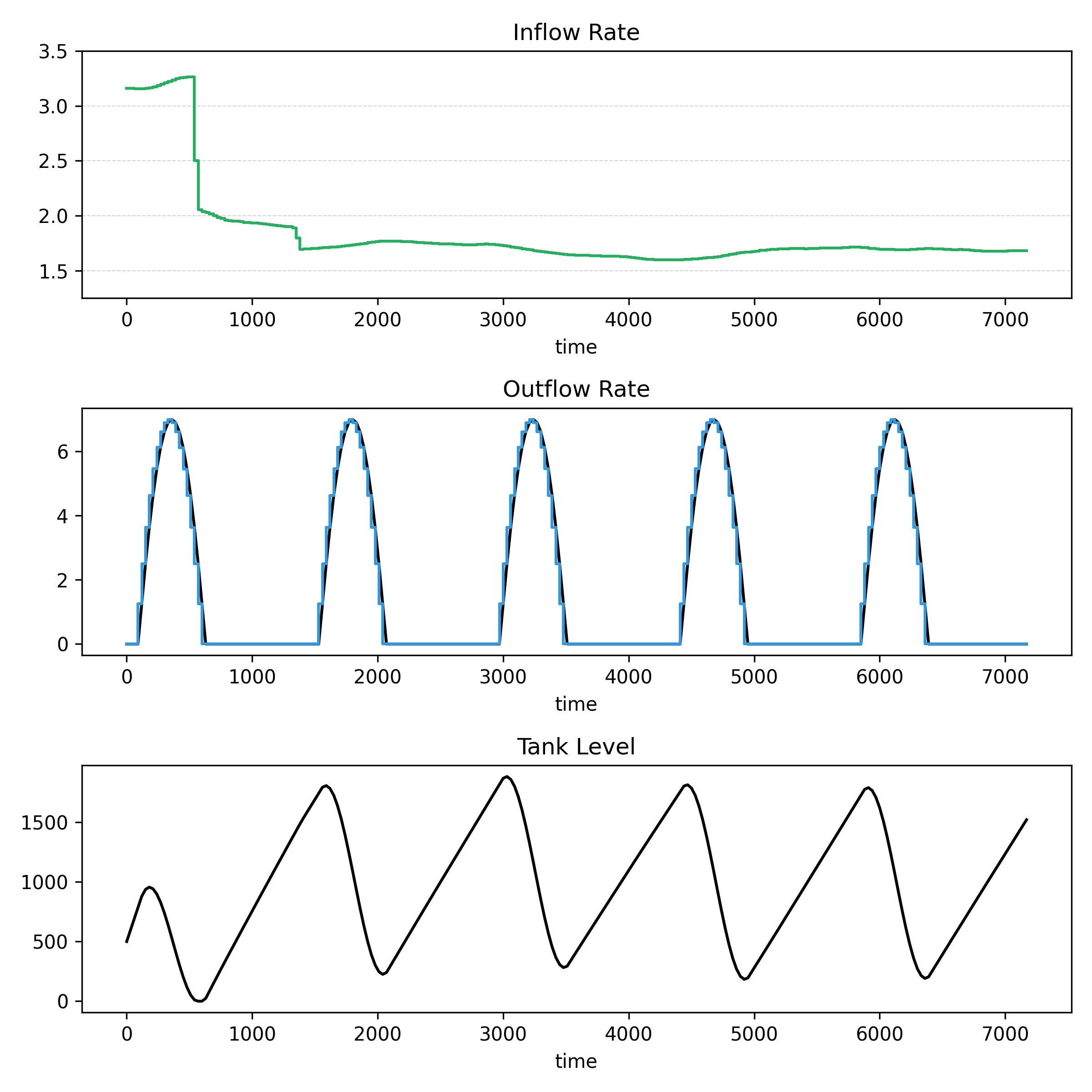
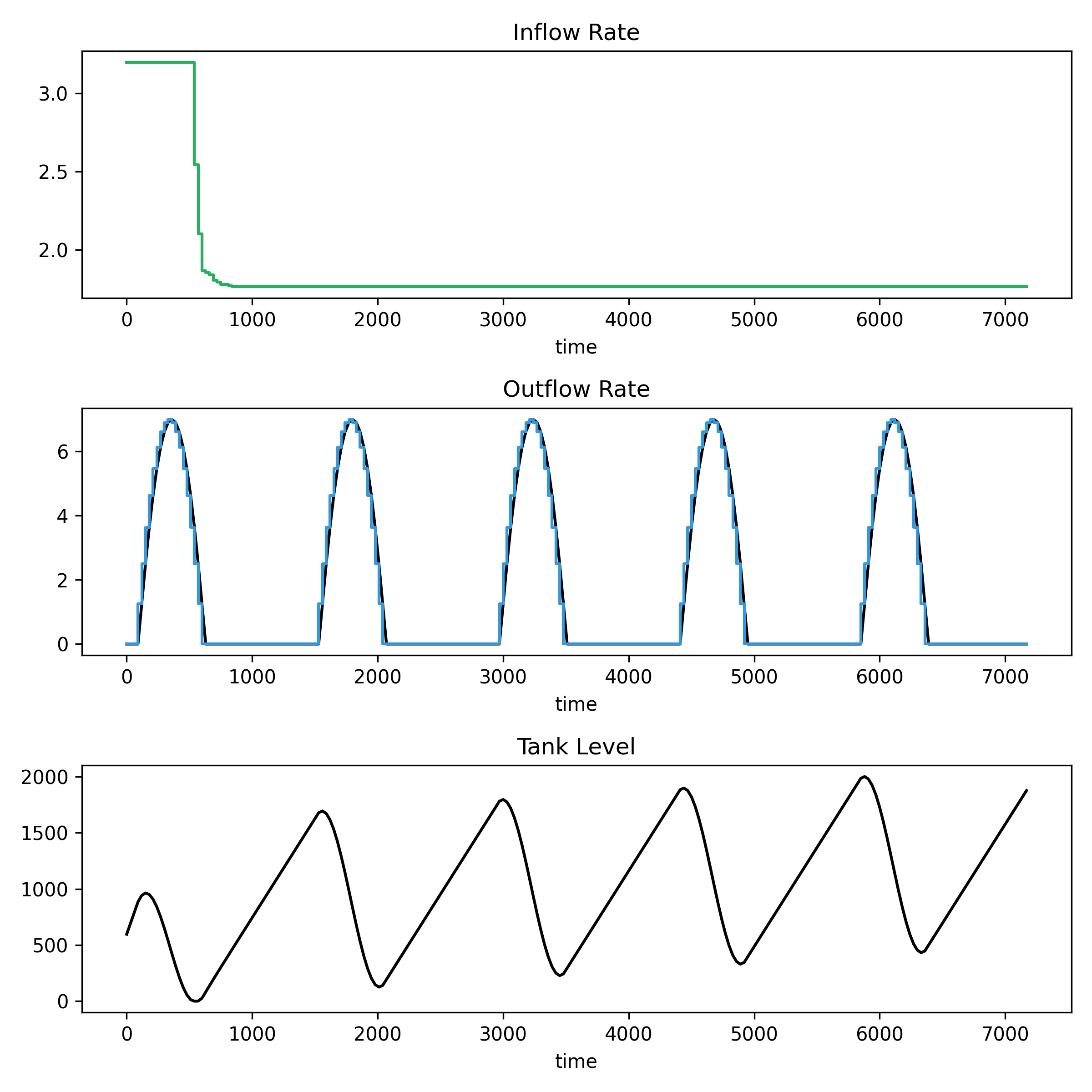
I’ve recently been given early access to a service that provides data on job listings published by a wide range of companies. The dataset offers a near real-time view of hiring activity, broken down at the company level. This is a potentially valuable signal for tracking labour market trends, ...