Want to share your content on python-bloggers? click here.
Combining the flexibility of data lakes with the reliability and performance of data warehouses, data lakehouses have become a cost-efficient and scalable option for businesses. The latest survey by Dremio suggests that 70% of data professionals believe that data lakehouses will power over half of their analytics within three years, and for many, it’s already happening. But what’s driving this shift? Why are businesses gravitating toward data lakehouses over traditional data management solutions? More importantly, if data lakehouse is the future of data management, how can you utilize this modern architecture to stay agile and scalable? Let’s understand all these aspects through this blog.
Data Warehouse vs. Data Lake vs. Data Lakehouse: How They Differ from Each Other

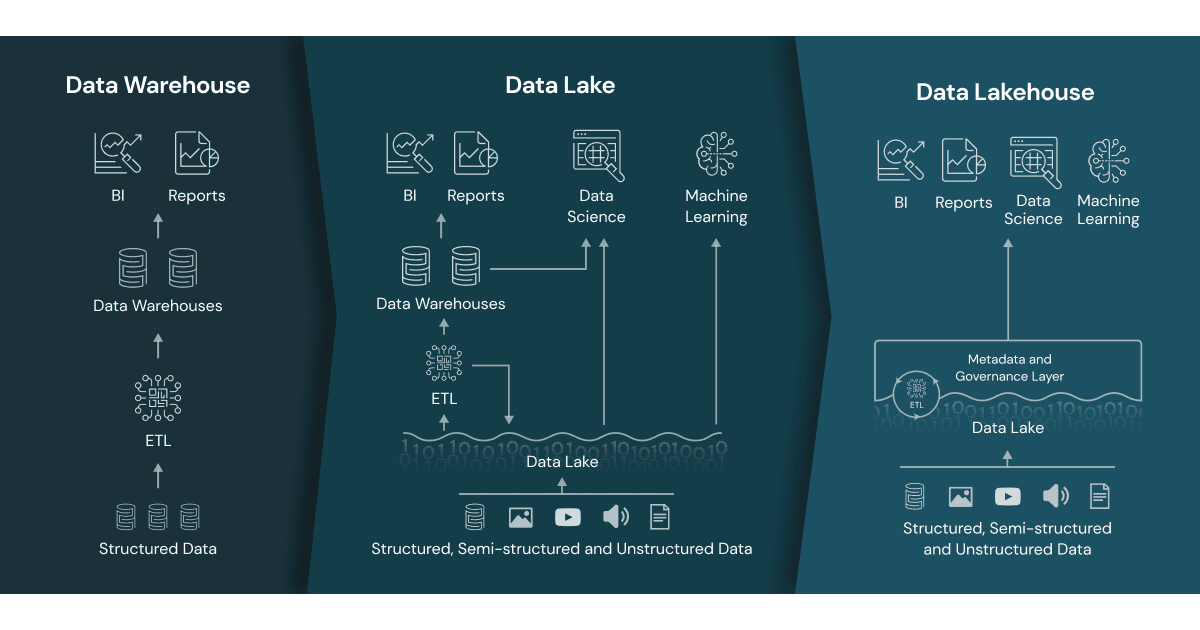
[Image Source: Data Bricks]
In the last few years, organizations have moved toward centralized and scalable data architectures and integrated AI and ML in data management to streamline processes. To address the complex needs of modern data, the architectures have also evolved – from data warehouses to data lakes and now the lakehouses.
Let’s understand how the limitations of one data architecture lead to the adoption of the next:
| Feature | Data Warehouse | Data Lake | Data Lakehouse |
| Purpose | Designed to handle structured databases, allowing organizations to derive insights from data collected from diverse sources | Designed for storing all types of databases- structured, semi-structured, and unstructured using open storage formats (such as Apache Parquet and Apache ORC) | Designed for handling structured, semi-structured, and unstructured data for analytics and business intelligence in a unified system, with transactional capabilities (ACID characteristics) |
| Data Processing Model | schema-on-write | schema-on-read | schema-on-read and write |
| Storage Cost | High, due to massive volumes of structured data and optimized querying | Low, cost-effective for storing large volumes of raw data | Low storage costs like data lakes, but with optimized querying like data warehouses |
| Data Types | Relational (SQL-based) | Non-relational (logs, files, multimedia, etc.) | Supports both relational and non-relational data types |
| Processing Speed | High for structured data | Slower due to large, unstructured datasets | High-speed analytics for both structured and unstructured data |
| Accessibility | Data must be processed before use, leading to higher latency | Raw data is accessible but not immediately queryable | Immediate query ability for raw and processed data |
| Scalability | Scales well for structured data, limited for unstructured | Highly scalable for raw and unstructured data | Scales for both structured and unstructured data with high efficiency |
| Data Governance | Strong governance and compliance for structured data | Limited governance and compliance mechanisms | Provides unified governance for all types of data |
| Analytics Capability | Advanced analytics for structured data | Limited analytics capability without complex ETL processes | Advanced analytics on both structured and unstructured data without ETL |
| Query Performance | High performance for structured queries (SQL) | Poor performance for analytics without pre-processing | High performance across all data types, optimized for analytical queries |
| Limitations | – Limited flexibility-Proprietary storage formats causing lock-in issuesLimited support for analytics | – Slower query processing speed- Lacks governance- Limited data security and access control features | – Emerging technology- Requires investment in new infrastructure |
| Adoption Drivers | The need for organized, structured data and high-performance queries | The need for low-cost, scalable storage of diverse data types (including unstructured and semi-structured datasets) | The need for a unified platform combining low-cost storage with advanced analytics and governance |
Understanding Data Lakehouse Architecture and its Underlying Technologies


[Image Source: Fivetran]
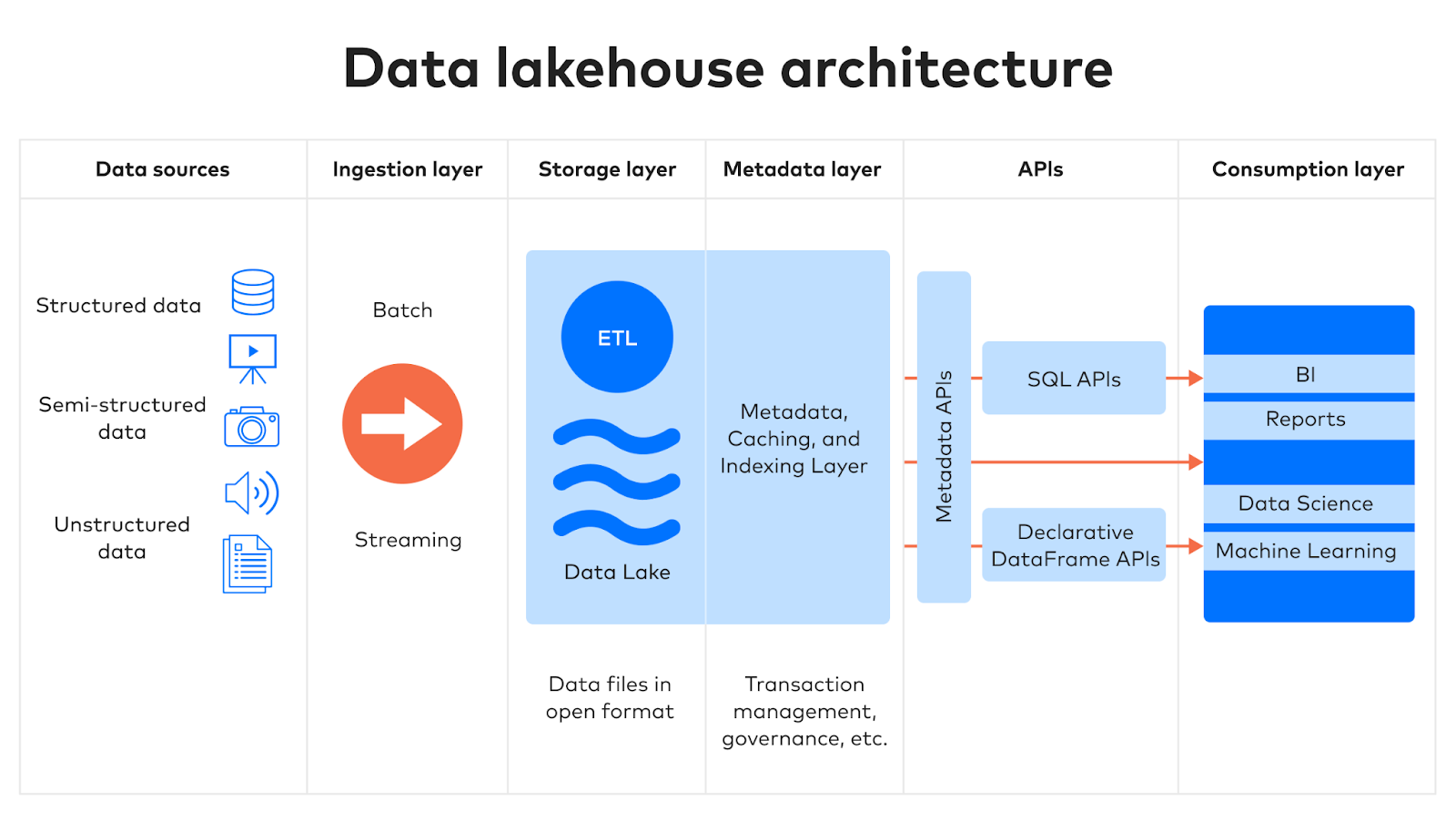{kind=link}
Built on a scalable and open architecture, lakehouses provide businesses with a flexible, cost-efficient, and future-proof solution for modern data management. This hybrid architecture merges the structure and speed of warehouses with the flexibility and scalability of lakes, resulting in a solution that’s faster, more powerful, and significantly more cost-effective. Five layers that make data lakehouses suitable for diverse use cases are:
Ingestion Layer
This layer is responsible for collecting structured, unstructured, and semi-structured data from diverse sources through various techniques and tools. The data can be ingested periodically (in batches) or in real-time into its raw form (Parquet files) and doesn’t process immediately (applying schema-on-read approach). Once all data is collected, the system transitions to a schema-on-write approach, applying transformation logic (format conversion, schema validation, etc.) to organize the data for specific tasks like machine learning models or running ad-hoc SQL queries.
Storage Layer
The data (with open-source file formats) is loaded into a low-cost data lake (can be cloud-based, such as Amazon S3).
Metadata Layer
Due to its exclusive presence in data lakehouse architecture, this layer holds significant importance and acts as a unified catalog of metadata for data lake objects. Some of the unique features/attributes of the metadata layer are:
- ACID transaction capabilities to ensure data integrity, consistency, and reliability
- Table-like schema to enhance the performance of RDBMS (Relational Database Management Systems)
- Schema governance and enforcement
- Access control to safeguard databases from online breaches
- Catching and In-memory data storage for fast retrieval
- Time-travel querying to access historical data
- New query engines to support high-performance SQL execution and analysis
API Layer
This layer hosts diverse APIs, allowing advanced analytical tools and machine learning applications to access data in open-source formats for diverse use cases.
Consumption Layer
Serving as the gateway for data access and analysis, this layer is particularly for data scientists and machine learning engineers. By supporting open data formats, such as Parquet and ORC, which are compatible with popular data science tools such as pandas, TensorFlow, and PyTorch, the consumption layer allows easy retrieval and analysis of data stored in the lakehouse.
Real-World Data Lakehouse Use Cases in Diverse Industries
The ability of data lakehouses to manage both structured and unstructured data and support AI and ML analytics makes them suitable for various use cases in different sectors. Here are some real-world applications of data lakehouses in various industries:
- Retail and eCommerce: Personalized Customer Experience
By providing a unified architecture, data lakehouse allows retail & eCommerce businesses to store raw transactional data in the lake while maintaining structured sales and inventory data in the warehouse. Machine learning models are applied to this data to offer personalized product recommendations in real time and optimize supply chain management.
Real-life example:
Walmart uses data lakehouse architectures to manage massive datasets, including customer transactions, website interactions, inventory data, and purchase histories.
- Healthcare: Real-Time Patient Data Analysis
Utilizing data lakehouse, unstructured IoT data (e.g., heart rate from wearables) alongside structured clinical data can be stored in a centralized repository. Through machine learning algorithms, this data can be analyzed to predict health trends and personalize treatment plans for patients.
Real-life examples:
GE Healthcare, Regeneron, ThermoFisher and Walgreens
- Financial Services: Fraud Detection and Risk Management
A data lakehouse enables real-time analysis of transactional data and customer behavior patterns, combining structured (bank statements, transaction records) and unstructured data (call logs, email communication). This integration supports advanced machine learning algorithms to identify anomalies and predict fraudulent activities.
Real-life examples:
Bank of America and JP Morgan Chase utilize data lakehouses for storing structured & unstructured data, detecting frauds and managing financial risks.
- Media and Entertainment: Content Personalization and Audience Analytics
A data lakehouse can ingest user interaction data such as clicks, viewing history, and ratings in real-time, enabling AI/ML algorithms to recommend relevant movies or songs based on user preferences.
Real-life examples:
Netflix and Shopify
Data Lakehouse Implementation – Challenges and Considerations Involved
While data lakehouses streamline advanced data management, their implementation comes with several challenges and considerations. Some of the key aspects you must consider are:
- Data Integration and Migration
One of the primary challenges in implementing a data lakehouse is integrating data from various sources and migrating existing data infrastructure. Organizations often deal with diverse data formats, ranging from structured (like databases) to semi-structured (JSON, XML) and unstructured (images, videos). Harmonizing these different data types into a unified architecture can be complex and time-consuming. Additionally, legacy data systems need to be migrated to the new infrastructure without disrupting ongoing operations, which requires careful planning.
Best Practices:
- Use ETL/ELT tools such as Apache NiFi, Talend, or AWS Glue that support multi-source data ingestion.
- Hire experts for data migration.
- Outsource data migration services to a reliable third-party provider who ensures zero data loss and minimum downtime.
- Cost Management
Building and maintaining a data lakehouse can be expensive, particularly when considering cloud infrastructure costs. Storing large volumes of raw and processed data, along with running complex analytics workloads, can lead to significant costs over time
Best Practices:
- Use tiered-storage solutions such as AWS, Azure, and Google Cloud to store frequently accessed data in faster (and more expensive) storage, while moving infrequently accessed data to cheaper, slower storage.
- Enable autoscaling features for compute resources to automatically adjust capacity based on workload, reducing costs during low usage periods.
- Utilize cloud cost monitoring tools like AWS Cost Explorer or Google Cloud’s Cost Management to monitor usage and optimize resource allocation to avoid unexpected expenses.
- Data Quality Management
Data lakehouses often ingest raw and unstructured data directly from source systems without much preprocessing. This can include redundant, missing, or incorrect information that might not meet quality standards. Utilizing such data for analytics can lead to inaccurate insights and business decisions.
Best Practices:
- Leverage automated tools such as Talend and Informatica to regularly monitor upcoming data and cleanse it to ensure accuracy, consistency, and reliability.
- Hire data professionals in-house to audit, cleanse, update, and validate data on a regular basis.
- Outsource data management services to a trusted third-party provider who can efficiently manage data standardization, cleansing, enrichment, and validation at a scale. It can be a viable option when you have time or resource constraints.
- Data Security Concerns
With a large amount of critical business data stored in a centralized repository, security is a significant concern. A single data breach can expose sensitive information to cyber attackers.
Best Practices:
- Implement a robust data governance framework to ensure data security and compliance. Assign data stewards or teams responsible for monitoring data quality, conducting routine checks, and addressing data quality issues timely.
- Implement end-to-end encryption for data at rest and in transit.
- Ensure strict role-based access control (RBAC) is in place, allowing data access only to authorized individuals
- Utilize real-time monitoring tools like Datadog, AWS CloudWatch, or Splunk to detect unusual activity and potential security threats.
- Implement multi-factor authentication for accessing the data lakehouse to add an extra layer of security.
Data Lakehouses – The Catalyst for Next-Generation Data Management Solutions
Data lakehouses are proving to be the future of big data management, offering a smarter, more flexible way to store, process, manage, and analyze critical data to stay ahead of the curve. However, to capitalize on its analytical and cost-effective storage capabilities, effective data integration is crucial. To ensure seamless data lakehouse implementation, you can utilize ETL tools, hire experts, or outsource data management services to a trusted provider. With the right implementation, data lakehouses can become more than just a data solution— a launchpad for smarter decisions, faster insights, and sustainable business success.
Want to share your content on python-bloggers? click here.