Want to share your content on python-bloggers? click here.
In the realm of statistical analysis, critical values and p-values serve as essential tools for hypothesis testing and decision making. These concepts, rooted in the work of statisticians like Ronald Fisher and the Neyman-Pearson approach, play a crucial role in determining statistical significance. Understanding the distinction between critical values and p-values is vital for researchers and data analysts to interpret their findings accurately and avoid misinterpretations that can lead to false positives or false negatives.
This article aims to shed light on the key differences between critical values and p-values in hypothesis testing. It will explore the definition and calculation of critical values, including how to find critical values using tables or calculators. The discussion will also cover p-values, their interpretation, and their relationship to significance levels. Additionally, the article will address common pitfalls in result interpretation and provide guidance on when to use critical values versus p-values in various statistical scenarios, such as t-tests and confidence intervals.

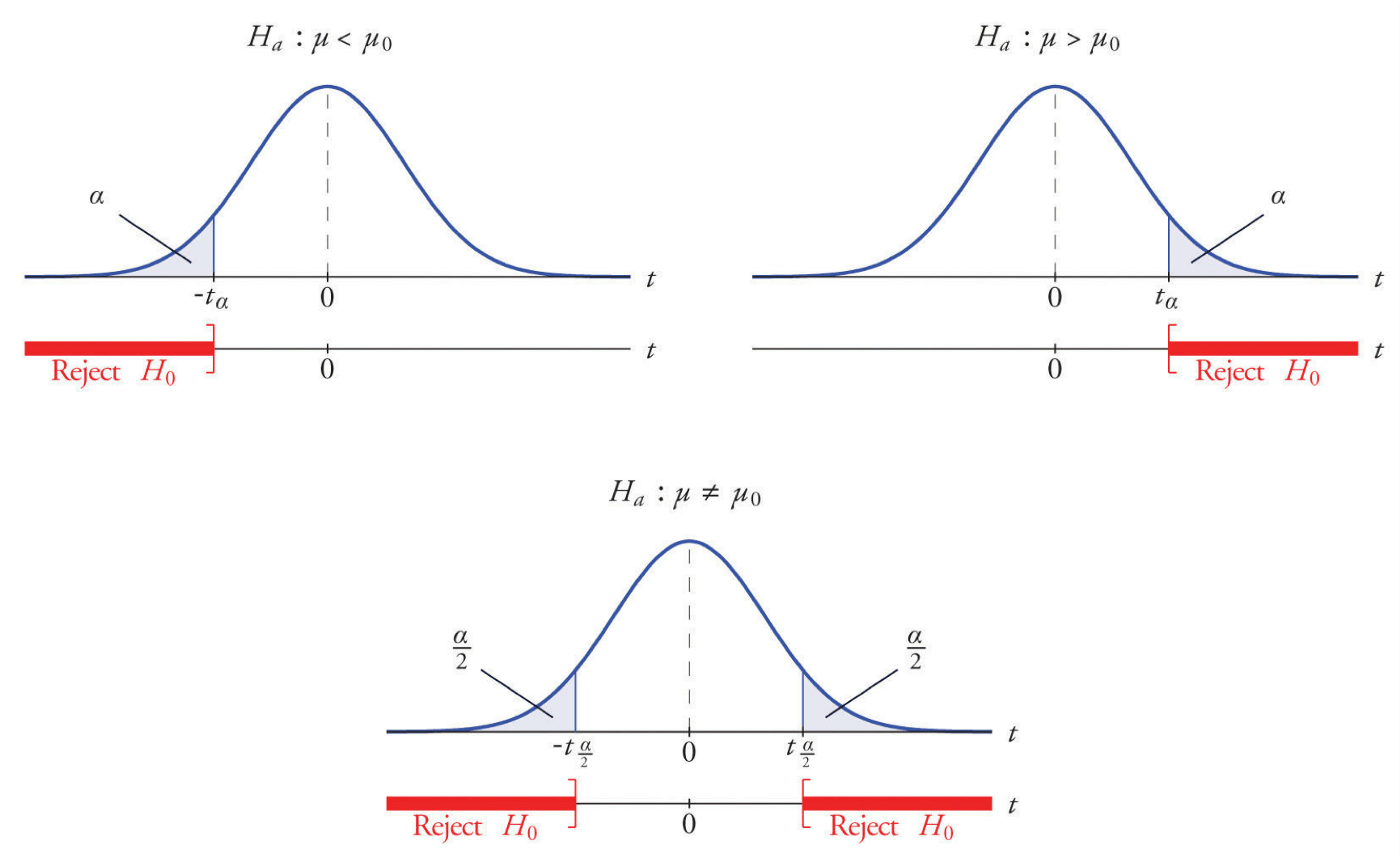
What is a Critical Value?
Definition and concept
A critical value in statistics serves as a crucial cut-off point in hypothesis testing and decision making. It defines the boundary between accepting and rejecting the null hypothesis, playing a vital role in determining statistical significance. The critical value is intrinsically linked to the significance level (α) chosen for the test, which represents the probability of making a Type I error.
Critical values are essential for accurately representing a range of characteristics within a dataset. They help statisticians calculate the margin of error and provide insights into the validity and accuracy of their findings. In hypothesis testing, the critical value is compared to the obtained test statistic to determine whether the null hypothesis should be rejected or not.
How to calculate critical values
Calculating critical values involves several steps and depends on the type of test being conducted. The general formula for finding the critical value is:
Critical probability (p*) = 1 – (Alpha / 2)
Where Alpha = 1 – (confidence level / 100)
For example, using a confidence level of 95%, the alpha value would be:
Alpha value = 1 – (95/100) = 0.05
Then, the critical probability would be:
Critical probability (p*) = 1 – (0.05 / 2) = 0.975
The critical value can be expressed in two ways:
- As a Z-score related to cumulative probability
- As a critical t statistic, which is equal to the critical probability
For larger sample sizes (typically n ≥ 30), the Z-score is used, while for smaller samples or when the population standard deviation is unknown, the t statistic is more appropriate.
Examples in hypothesis testing
Critical values play a crucial role in various types of hypothesis tests. Here are some examples:
- One-tailed test: For a right-tailed test with H₀: μ = 3 vs. H₁: μ > 3, the critical value would be the t-value such that the probability to the right of it is α. For instance, with α = 0.05 and 14 degrees of freedom, the critical value t₀.₀₅,₁₄ is 1.7613. The null hypothesis would be rejected if the test statistic t is greater than 1.7613.
- Two-tailed test: For a two-tailed test with H₀: μ = 3 vs. H₁: μ ≠ 3, there are two critical values – one for each tail. Using α = 0.05 and 14 degrees of freedom, the critical values would be -2.1448 and 2.1448. The null hypothesis would be rejected if the test statistic t is less than -2.1448 or greater than 2.1448.
- Z-test example: In a tire manufacturing plant producing 15.2 tires per hour with a variance of 2.5, new machines were tested. The critical region for a one-tailed test with α = 0.10 was z > 1.282. The calculated z-statistic of 3.51 exceeded this critical value, leading to the rejection of the null hypothesis.
Understanding critical values is essential for making informed decisions in hypothesis testing and statistical analysis. They provide a standardized approach to evaluating the significance of research findings and help researchers avoid misinterpretations that could lead to false positives or false negatives.
Understanding P-Values

Definition of p-value
In statistical hypothesis testing, a p-value is a crucial concept that helps researchers quantify the strength of evidence against the null hypothesis. The p-value is defined as the probability of obtaining test results at least as extreme as the observed results, assuming that the null hypothesis is true. This definition highlights the relationship between the p-value and the null hypothesis, which is fundamental to understanding its interpretation.
The p-value serves as an alternative to rejection points, providing the smallest level of significance at which the null hypothesis would be rejected. It is important to note that the p-value is not the probability that the null hypothesis is true or that the alternative hypothesis is false. Rather, it indicates how compatible the observed data are with a specified statistical model, typically the null hypothesis.
Interpreting p-values
Interpreting p-values correctly is essential for making sound statistical inferences. A smaller p-value suggests stronger evidence against the null hypothesis and in favor of the alternative hypothesis. Conventionally, a p-value of 0.05 or lower is considered statistically significant, leading to the rejection of the null hypothesis. However, it is crucial to understand that this threshold is arbitrary and should not be treated as a definitive cutoff point for decision-making.
When interpreting p-values, it is important to consider the following:
- The p-value does not indicate the size or importance of the observed effect. A small p-value can be observed for an effect that is not meaningful or important, especially with large sample sizes.
- The p-value is not the probability that the observed effects were produced by random chance alone. It is calculated under the assumption that the null hypothesis is true.
- A p-value greater than 0.05 does not necessarily mean that the null hypothesis is true or that there is no effect. It simply indicates that the evidence against the null hypothesis is not strong enough to reject it at the chosen significance level.
Common misconceptions about p-values
Despite their widespread use, p-values are often misinterpreted in scientific research and education. Some common misconceptions include:
- Interpreting the p-value as the probability that the null hypothesis is true or the probability that the alternative hypothesis is false. This interpretation is incorrect, as p-values do not provide direct probabilities for hypotheses.
- Believing that a p-value less than 0.05 proves that a finding is true or that the probability of making a mistake is less than 5%. In reality, the p-value is a statement about the relation of the data to the null hypothesis, not a measure of truth or error rates.
- Treating p-values on opposite sides of the 0.05 threshold as qualitatively different. This dichotomous thinking can lead to overemphasis on statistical significance and neglect of practical significance.
- Using p-values to determine the size or importance of an effect. P-values do not provide information about effect sizes or clinical relevance.
To address these misconceptions, it is important to consider p-values as continuous measures of evidence rather than binary indicators of significance. Additionally, researchers should focus on reporting effect sizes, confidence intervals, and practical significance alongside p-values to provide a more comprehensive understanding of their findings.
Key Differences Between Critical Values and P-Values
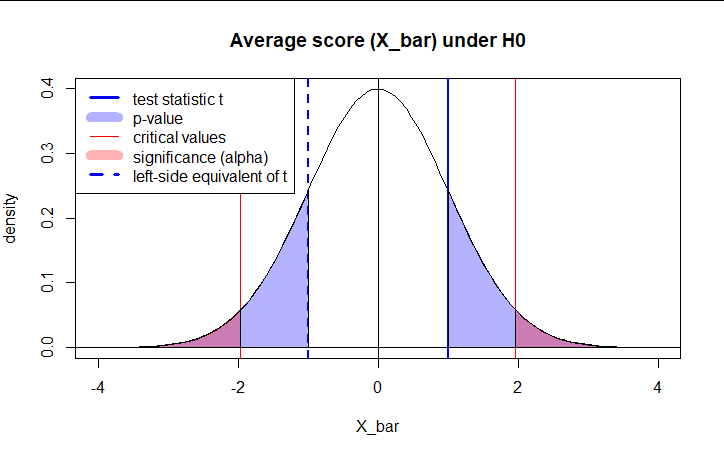
Approach to hypothesis testing
Critical values and p-values represent two distinct approaches to hypothesis testing, each offering unique insights into the decision-making process. The critical value approach, rooted in traditional hypothesis testing, establishes a clear boundary for accepting or rejecting the null hypothesis. This method is closely tied to significance levels and provides a straightforward framework for statistical inference.
In contrast, p-values offer a continuous measure of evidence against the null hypothesis. This approach allows for a more nuanced evaluation of the data’s compatibility with the null hypothesis. While both methods aim to support or reject the null hypothesis, they differ in how they lead to that decision.
Decision-making process
The decision-making process for critical values and p-values follows different paths. Critical values provide a binary framework, simplifying the decision to either reject or fail to reject the null hypothesis. This approach streamlines the process by classifying results as significant or not significant based on predetermined thresholds.
For instance, in a hypothesis test with a significance level (α) of 0.05, the critical value serves as the dividing line between the rejection and non-rejection regions. If the test statistic exceeds the critical value, the null hypothesis is rejected.
P-values, on the other hand, offer a more flexible approach to decision-making. Instead of a simple yes or no answer, p-values present a range of evidence levels against the null hypothesis. This continuous scale allows researchers to interpret the strength of evidence and choose an appropriate significance level for their specific context.
Interpretation of results
The interpretation of results differs significantly between critical values and p-values. Critical values provide a clear-cut interpretation: if the test statistic falls within the rejection region defined by the critical value, the null hypothesis is rejected. This approach offers a straightforward way to communicate results, especially when a binary decision is required.
P-values, however, offer a more nuanced interpretation of results. A smaller p-value indicates stronger evidence against the null hypothesis. For example, a p-value of 0.03 suggests more compelling evidence against the null hypothesis than a p-value of 0.07. This continuous scale allows for a more detailed assessment of the data’s compatibility with the null hypothesis.
It’s important to note that while a p-value of 0.05 is often used as a threshold for statistical significance, this is an arbitrary cutoff. The interpretation of p-values should consider the context of the study and the potential for practical significance.
Both approaches have their strengths and limitations. Critical values simplify decision-making but may not accurately reflect the increasing precision of estimates as sample sizes grow. P-values provide a more comprehensive understanding of outcomes, especially when combined with effect size measures. However, they are frequently misunderstood and can be affected by sample size in large datasets, potentially leading to misleading significance.
In conclusion, while critical values and p-values are both essential tools in hypothesis testing, they offer different perspectives on statistical inference. Critical values provide a clear, binary decision framework, while p-values allow for a more nuanced evaluation of evidence against the null hypothesis. Understanding these differences is crucial for researchers to choose the most appropriate method for their specific research questions and to interpret results accurately.

When to Use Critical Values vs. P-Values
Advantages of critical value approach
The critical value approach offers several advantages in hypothesis testing. It provides a simple, binary framework for decision-making, allowing researchers to either reject or fail to reject the null hypothesis. This method is particularly useful when a clear explanation of the significance of results is required. Critical values are especially beneficial in sectors where decision-making is influenced by predetermined thresholds, such as the commonly used 0.05 significance level.
One of the key strengths of the critical value approach is its consistency with accepted significance levels, which simplifies interpretation. This method is particularly valuable in non-parametric tests where distributional assumptions may be violated. The critical value approach involves comparing the observed test statistic to a predetermined cutoff value. If the test statistic is more extreme than the critical value, the null hypothesis is rejected in favor of the alternative hypothesis.
Benefits of p-value method
The p-value method offers a more nuanced approach to hypothesis testing. It provides a continuous scale for evaluating the strength of evidence against the null hypothesis, allowing researchers to interpret data with greater flexibility. This approach is particularly useful when conducting unique or exploratory research, as it enables scientists to choose an appropriate level of significance based on their specific context.
P-values quantify the probability of observing a test statistic as extreme as, or more extreme than, the one observed, assuming the null hypothesis is true. This method provides a more comprehensive understanding of outcomes, especially when combined with effect size measures. For instance, a p-value of 0.0127 indicates that it is unlikely to observe such an extreme test statistic if the null hypothesis were true, leading to its rejection.
Choosing the right approach for your study
The choice between critical values and p-values depends on various factors, including the nature of the data, study design, and research objectives. Critical values are best suited for situations requiring a simple, binary choice about the null hypothesis. They streamline the decision-making process by classifying results as significant or not significant.
On the other hand, p-values are more appropriate when evaluating the strength of evidence against the null hypothesis on a continuous scale. They offer a more subtle understanding of the data’s significance and allow for flexibility in interpretation. However, it’s crucial to note that p-values have been subject to debate and controversy, particularly in the context of analyzing complex data associated with plant and animal breeding programs.
When choosing between these approaches, consider the following:
- If you need a clear-cut decision based on predetermined thresholds, the critical value approach may be more suitable.
- For a more nuanced interpretation of results, especially in exploratory research, the p-value method might be preferable.
- Consider the potential for misinterpretation and misuse associated with p-values, such as p-value hacking, which can lead to inflated significance and misleading conclusions.
Ultimately, the choice between critical values and p-values should be guided by the specific requirements of your study and the need for accurate statistical inferences to make informed decisions in your field of research.
Common Pitfalls in Interpreting Results
Overreliance on arbitrary thresholds
One of the most prevalent issues in statistical analysis is the overreliance on arbitrary thresholds, particularly the p-value of 0.05. This threshold has been widely used for decades to determine statistical significance, but its arbitrary nature has come under scrutiny. Many researchers argue that setting a single threshold for all sciences is too extreme and can lead to misleading conclusions.
The use of p-values as the sole measure of significance can result in the publication of potentially false or misleading results. It’s crucial to understand that statistical significance does not necessarily equate to practical significance or real-world importance. A study with a large sample size can produce statistically significant results even when the effect size is trivial.
To address this issue, some researchers propose selecting and justifying p-value thresholds for experiments before collecting any data. These levels would be based on factors such as the potential impact of a discovery or how surprising it would be. However, this approach also has its critics, who argue that researchers may not have the incentive to use more stringent thresholds of evidence.
Ignoring effect sizes
Another common pitfall in interpreting results is the tendency to focus solely on statistical significance while ignoring effect sizes. Effect size is a crucial measure that indicates the magnitude of the relationship between variables or the difference between groups. It provides information about the practical significance of research findings, which is often more valuable than mere statistical significance.
Unlike p-values, effect sizes are independent of sample size. This means they offer a more reliable measure of the practical importance of a result, especially when dealing with large datasets. Researchers should report effect sizes alongside p-values to provide a comprehensive understanding of their findings.
It’s important to note that the criteria for small or large effect sizes may vary depending on the research field. Therefore, it’s essential to consider the context and norms within a particular area of study when interpreting effect sizes.
Misinterpreting statistical vs. practical significance
The distinction between statistical and practical significance is often misunderstood or overlooked in research. Statistical significance, typically determined by p-values, indicates the probability that the observed results occurred by chance. However, it does not provide information about the magnitude or practical importance of the effect.
Practical significance, on the other hand, refers to the real-world relevance or importance of the research findings. A result can be statistically significant but practically insignificant, or vice versa. For instance, a study with a large sample size might find a statistically significant difference between two groups, but the actual difference may be too small to have any meaningful impact in practice.
To avoid this pitfall, researchers should focus on both statistical and practical significance when interpreting their results. This involves considering not only p-values but also effect sizes, confidence intervals, and the potential real-world implications of the findings. Additionally, it’s crucial to interpret results in the context of the specific research question and field of study.
By addressing these common pitfalls, researchers can improve the quality and relevance of their statistical analyzes. This approach will lead to more meaningful interpretations of results and better-informed decision-making in various fields of study.
Conclusion
Critical values and p-values are key tools in statistical analysis, each offering unique benefits to researchers. These concepts help in making informed decisions about hypotheses and understanding the significance of findings. While critical values provide a clear-cut approach for decision-making, p-values offer a more nuanced evaluation of evidence against the null hypothesis. Understanding their differences and proper use is crucial to avoid common pitfalls in result interpretation.
Ultimately, the choice between critical values and p-values depends on the specific needs of a study and the context of the research. It’s essential to consider both statistical and practical significance when interpreting results, and to avoid overreliance on arbitrary thresholds. By using these tools wisely, researchers can enhance the quality and relevance of their statistical analyzes, leading to more meaningful insights and better-informed decisions.
FAQs
1. When should you use a critical value as opposed to a p-value in hypothesis testing?
When testing a hypothesis, compare the p-value directly with the significance level (α). If the p-value is less than α, reject the null hypothesis (H0); if it’s greater, do not reject H0. Conversely, using critical values allows you to determine whether the p-value is greater or less than α.
2. What does it mean if the p-value is less than the critical value?
If the p-value is lower than the critical value, you should reject the null hypothesis. Conversely, if the p-value is equal to or greater than the critical value, you should not reject the null hypothesis. Remember, a smaller p-value generally indicates stronger evidence against the null hypothesis.
3. What is the purpose of a critical value in statistical testing?
The critical value is a point on the test statistic that defines the boundaries of the acceptance or rejection regions for a statistical test. It helps in setting the threshold for what constitutes statistically significant results.
4. When should you reject the null hypothesis based on the critical value?
In the critical value approach, if the test statistic is more extreme than the critical value, reject the null hypothesis. If it is less extreme, do not reject the null hypothesis. This method helps in deciding the statistical significance of the test results.

Unlock the power of data science & AI with Tesseract Academy! Dive into our data science & AI courses to elevate your skills and discover endless possibilities in this new era.
Want to share your content on python-bloggers? click here.