What Are Recommendation Engines and How Do They Work in Layman’s Terms?
Want to share your content on python-bloggers? click here.
The journey began on Twitter, or X, as it is now called. You saw an interesting tweet and after what may have been a few kilometers of scrolling, you serendipitously—or so you think—stumbled upon a YouTube link. This led to a few hours of uninterrupted immersion in a stream of videos. Hours later, you regained your sense of self and emerged from the rabbit hole you had fallen into. You felt a slight guilt but you quickly brushed that aside; as compensation, you have an assortment of esoteric knowledge that none of your peers know.
What is described is recommendation engines or algorithms casting their spell on you. Falling into a rabbit hole is just one of the traps of recommendation systems. Filter bubbles, social media addiction, radicalization, and manipulation are some other notorious pitfalls. Modern recommender systems are so good that they are bad—for the end-user, that is.
What is a recommendation engine and why does it have such a stranglehold over us? Curious? Let us find out. Don’t worry, there are no rabbit holes here.
Recommendation engines: simply explained
A recommendation or recommender engine—also known by various other names such as recommendation or recommender system, algorithm, or platform—is an information filtering system that serves users with the most relevant content. It is a subset of machine learning and makes predictions about what to suggest to users using data.
The data may be about the user (search history, clicks, views, age, location, etc.), other users with similar characteristics, or/and the items. A recommendation engine uses these disparate data sets to provide recommendations; the most significant of them being the user’s data. Thus, generally, the more detailed and accurate the user’s data, the better the system’s prediction. And this rests largely on data collection. Consequently, the more you interact with the system, the better its recommendation.
Besides the data—users’ and items’—which constitute two of three components of a recommendation system, a third component, the filtering techniques, is used to filter items and make suggestions that align with the user’s interests.
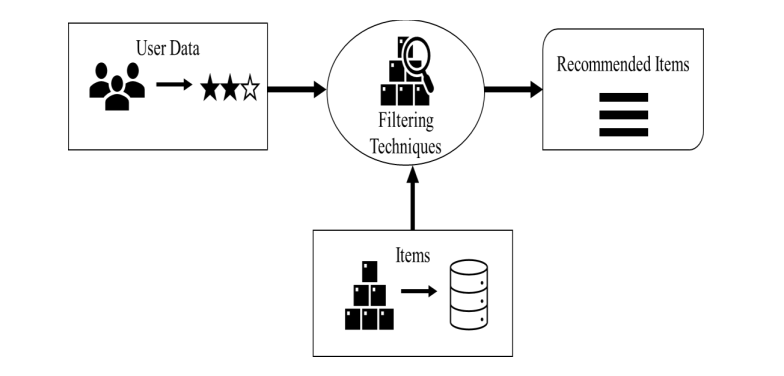
Recommendation system: a general architecture | Source
A recommendation engine typically consists of two sets and a utility function. User data go into the user set and all items that can be recommended along with their associated data are contained in the item set. The utility function assesses the likelihood of an item matching the preference of a user and makes the recommendation.
This is the basis of the recommendation method called matrix factorization, in which the user-item interactions are represented in a matrix. This method has however been largely superseded by deep learning. There has occurred a paradigmatic shift in recommendation systems as a result.
Shown in the image below is the structure of a recommendation engine comprising two neural networks: candidate generation and ranking. These two networks work in concert to provide the most relevant content, by using data from the user’s activity and history as input. A score is then assigned to the item using a number of features that describe the item and the user. This score is then used to make recommendations: items are presented to the user based on the score, starting with the highest.
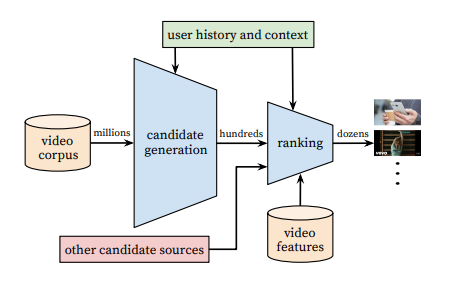
An example of a recommendation engine with two neural networks | Source
Types of recommendation engines
Most recommendation engines use one of two approaches or techniques to filter items or content and suggest the most relevant: content-based filtering, collaborative filtering, or a hybrid of the two.
- Content-based filtering
In the content-based approach, recommendations are made based on the features of an item or its content, the behavior of the user, and the preferences exhibited in the past. The basic principle of content-based filtering is, if you like a certain item, then you also like similar items. The problem, or rather the objective, here is thus to search and select items most similar to what the target user prefers.
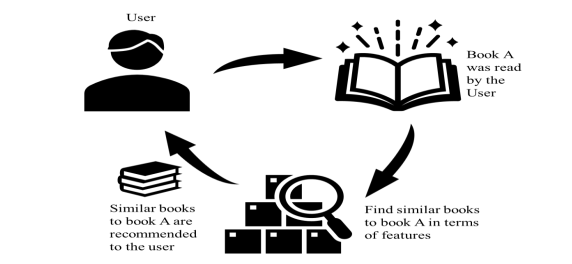
An illustration of content-based filtration method | Source
To precisely or approximately gauge the likelihood, items are assigned attributes—such as color, taste, and brand—that are used to compare other items. The attributes are given weights which are used to determine the priority of appearance in a recommendation system.
For this technique to work well, thorough and accurate annotation of data sets is requisite. This is a daunting task that may be approached expediently by getting a suitable data annotation service from a third party.
- Collaborative filtering
This technique uses data generated by users to compare and identify their preferences. The assumed premise in this approach is: if users similar to you like an item, then you’ll also like it, too.
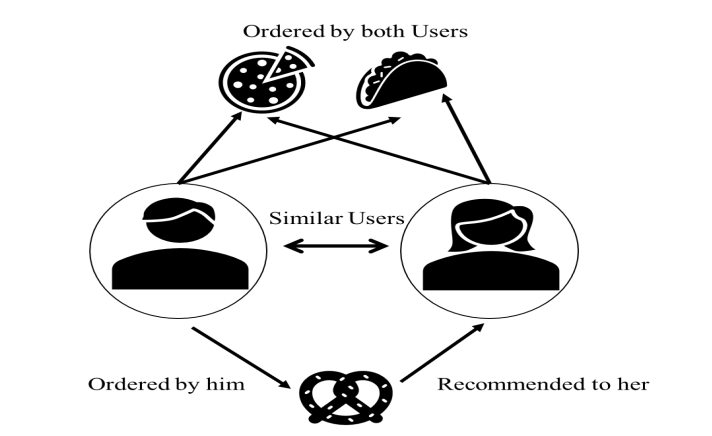
A simple representation of collaborative filtering technique | Source
Unlike content-based filtering, collaborative filtering doesn’t rely on product features but on users’ profiles. Similarities between items are based on which users like them. This entails that a collaborative filtering system works well without understanding the items. But it is not without ills.
Personalization of recommendations is difficult when user data are sparse, especially when the number of items far exceeds that of users. Another prominent challenge is the “cold start problem”: new users without feedback or ratings are left out of the loop.

Procedure of collaborative filtering approach | Source
- Hybrid filtering
Both content-based and collaborative approaches have some inherent weaknesses. Content-based filtering is good for personalization but collaborative filtering is not; and the collaborative approach can be helpful for introducing novel items while the content-based approach is not. A hybrid of these harnesses their strengths while mitigating the weaknesses of each. The scores from the two systems may be combined in different ways.
An example of the hybrid filtering method | Source
They can be hybridized numerically simultaneously, run after the other using one as the input for the other, switched based on specific criteria, or the results of one may be used to refine the other’s. This combined approach enhances the predictive performance and accuracy of the recommendation engine. At the cost of this is an increase in cost, complexity, and data on a cosmic scale.
Let us try to understand better how a recommendation engine works.
How does a recommendation engine work?
Recommendation engines work in basically one of two ways. They suggest items that a user is likely to be interested in based on what they like (item-based recommendation) or items that similar users like (user-based recommendation). The recommendation engine relies on the features and content of items and the user data to compute the relationship between suggests the most relevant. This is generally done using what is known in deep learning as “two towers” modeling.
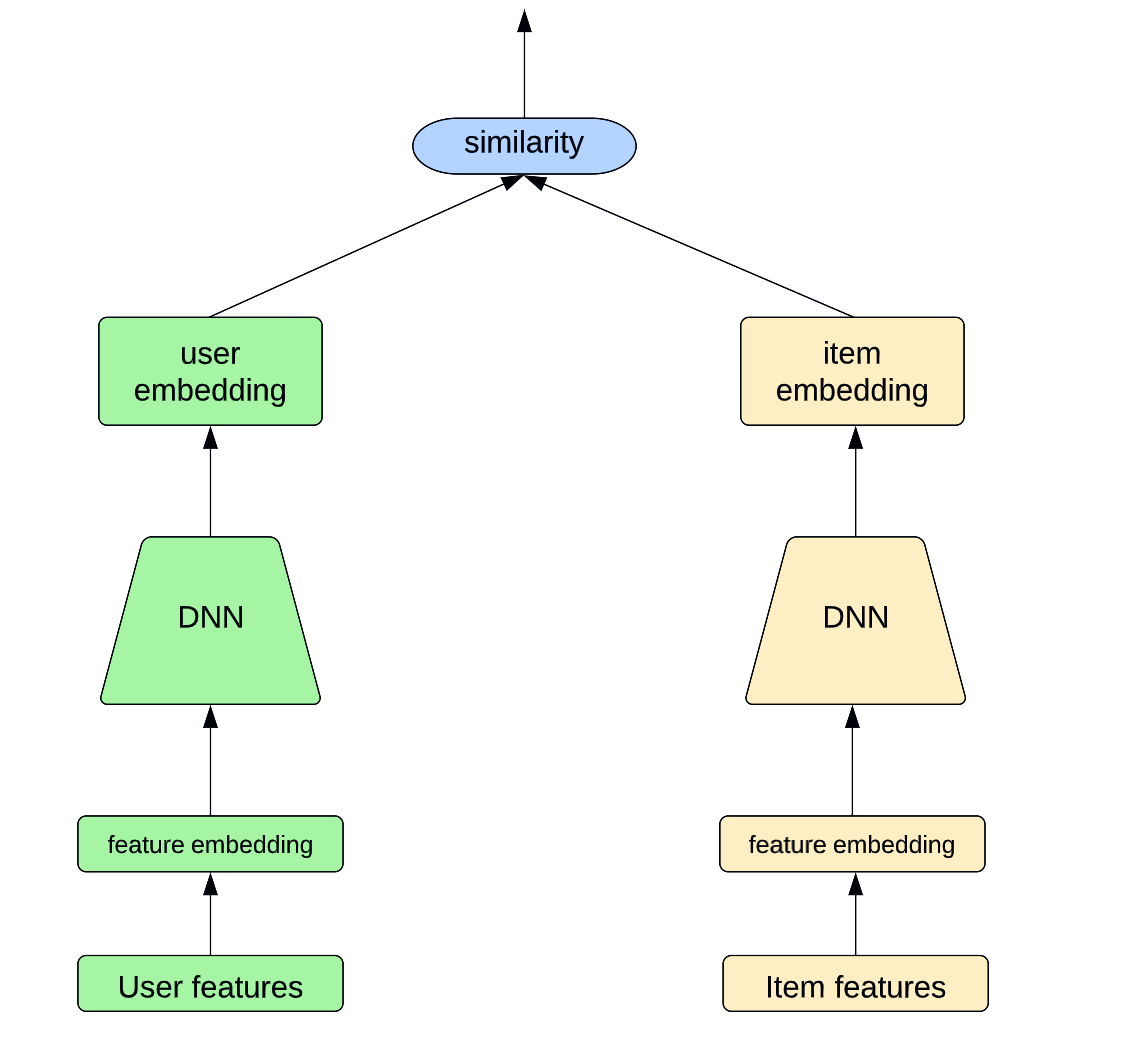
Representation of the “two towers” modeling for personalized recommendation | Source
The task of a recommendation engine is to use data to make accurate predictions of users’ possible likes and interests. This seemingly simple task involves complex operations using large volumes of data and various techniques to identify patterns. This can be broadly divided into three phases, although the minutiae varies depending on the technique.
- Data collection and preparation
The recommendation engine needs a wide variety and volume of information about users in order to provide reasonable suggestions. Other things equal, the better it knows about the user, the better its recommendation. It collects different types of data such as explicit user feedback like ratings and reviews, and implicit feedback which may be inferred from users’ activities.
Once the data have been compiled, they need to be prepared and their integrity processed before they are ready for the subsequent phases. The features of items are described so that they can be represented. This may be done by extracting information from the item’s source or annotating. The whole or a part of this phase can be delegated to a data Management services provider.
- Prediction and ranking
The user profiles and the item profiles are classified into different categories of features between items or users. This phase can include several different processes to deliver a unified prediction on a user-by-user basis. However, since ranking each item for every user is practically infeasible—the computational power required and the time taken would be prohibitively high—search algorithms such as approximate nearest neighbor are used.
Prediction is typically done by calculating a score or ranking for each item based on its estimated relevance for a particular user. Different types of prediction algorithms may be used depending on the recommendation approach and desired accuracy. Some common ones include k-nearest neighbor, matrix factorization, and decision trees.
The prediction algorithm uses historical records or user ratings and activities and item-related characteristics to make recommendations. It aims to predict the ranking or score of items for specific users through a utility function.
- Recommendation
By comparing the user’s profile with the items’ features, a score is established. A list of items is presented to the user, in the order of their ranks.
This phase involves filtering out irrelevant or inappropriate items based on factors such as user preferences, item popularity, and diversity of recommendations. One of the filtering techniques is used to refine the prediction.
Recommendation: it’s not just about accuracy
The key goal of any recommendation engine is to provide accurate and relevant suggestions. But it is not the only factor that matters. While reducing information overload and reducing the choice for users to a digestible number is important, it is important not to overlook other factors such as novelty, diversity, and serendipity. Many of the issues of recommendation engines have been because of the shortfalls in some of these less-considered factors and not because they fall short of inaccuracy.
YouTube’s recommendation algorithms, for example, drive 70% of what people watch on the platform. Recommendation engines give users what they want—or perhaps not—and in exchange take away their choice.
The post What Are Recommendation Engines and How Do They Work in Layman’s Terms? first appeared on The Data Scientist.
Want to share your content on python-bloggers? click here.